Retrieval for Unstructured Data
Motivation
Language models (LLMs) are trained on vast but fixed datasets, which limits their ability to access up-to-date or domain-specific information.
To enhance their performance on specific tasks, we can augment their knowledge using retrieval systems.
Retrieval systems fetch relevant information from external sources, which can then be included in the prompt given to the model.
Key benefits of using retrieval systems include:
- Access to recent or private information
- Improved accuracy on domain-specific tasks
- Reduced hallucination by grounding responses in retrieved facts
- Cost-effective alternative to fine-tuning for factual recall
Un-Structured Data
Vector stores are a type of retrieval system that work with unstructured data.
Unstructured documents (e.g., raw text, tables, images) are often embedded into a compressed representation (e.g., a vector) that can used directly for search based upon similarity to an input query.
Query Translation
Vector-based similarity search can be sensitive to the query used to retrieve similar documents.
Yet, ideally, a retrieval system can handle a wide range of (user) inputs, from poorly worded questions to complex multi-part queries.
A popular approch is to use an LLM to review and optionally modify the input is the central idea behind query translation.
This serves as a general buffer, optimizing raw user inputs for your retrieval system.
For example, this can be as simple as extracting keywords or as complex as generating multiple sub-questions for a complex query.
| Name | When to use | Description |
|---|---|---|
| Multi-query | When you need to cover multiple perspectives of a question. | Rewrite the user question from multiple perspectives, retrieve documents for each rewritten question, return the unique documents for all queries. |
| Decomposition | When a question can be broken down into smaller subproblems. | Decompose a question into a set of subproblems / questions, which can either be solved sequentially (use the answer from first + retrieval to answer the second) or in parallel (consolidate each answer into final answer). |
| Step-back | When a higher-level conceptual understanding is required. | First prompt the LLM to ask a generic step-back question about higher-level concepts or principles, and retrieve relevant facts about them. Use this grounding to help answer the user question. Paper. |
| HyDE | If you have challenges retrieving relevant documents using the raw user inputs. | Use an LLM to convert questions into hypothetical documents that answer the question. Use the embedded hypothetical documents to retrieve real documents with the premise that doc-doc similarity search can produce more relevant matches. Paper. |
See our RAG from Scratch videos for a few different specific approaches:
Indexing Strategies
Documents needed to be indexed, frequently using embedding models to compress the semantic information in documents to fixed-size vectors.
Many RAG approaches focus on splitting documents into chunks and retrieving some number based on similarity to an input question for the LLM.
But chunk size and chunk number can be difficult to set and affect results if they do not provide full context for the LLM to answer a question.
Furthermore, LLMs are increasingly capable of processing millions of tokens.
Two approaches can address this tension:
(1) Multi Vector retriever using an LLM to translate documents into any form (e.g., often into a summary) that is well-suited for indexing, but returns full documents to the LLM for generation.
(2) ParentDocument retriever embeds document chunks, but also returns full documents. The idea is to get the best of both worlds: use concise representations (summaries or chunks) for retrieval, but use the full documents for answer generation.
| Name | Index Type | Uses an LLM | When to Use | Description |
|---|---|---|---|---|
| Vector store | Vector store | No | If you are just getting started and looking for something quick and easy. | This is the simplest method and the one that is easiest to get started with. It involves creating embeddings for each piece of text. |
| ParentDocument | Vector store + Document Store | No | If your pages have lots of smaller pieces of distinct information that are best indexed by themselves, but best retrieved all together. | This involves indexing multiple chunks for each document. Then you find the chunks that are most similar in embedding space, but you retrieve the whole parent document and return that (rather than individual chunks). |
| Multi Vector | Vector store + Document Store | Sometimes during indexing | If you are able to extract information from documents that you think is more relevant to index than the text itself. | This involves creating multiple vectors for each document. Each vector could be created in a myriad of ways - examples include summaries of the text and hypothetical questions. |
| Time-Weighted Vector store | Vector store | No | If you have timestamps associated with your documents, and you want to retrieve the most recent ones | This fetches documents based on a combination of semantic similarity (as in normal vector retrieval) and recency (looking at timestamps of indexed documents) |
- See our RAG from Scratch video on indexing fundamentals
- See our RAG from Scratch video on multi vector retriever
Search Strategies
There are a few ways to improve the quality of similarity search.
Embedding models compress text into fixed-length (vector) representations that capture the semantic content of the document.
This compression is useful for search / retrieval, but puts a heavy burden on that single vector representation to capture the semantic nuance / detail of the document.
In some cases, irrelevant or redundant content can dilute the semantic usefulness of the embedding.
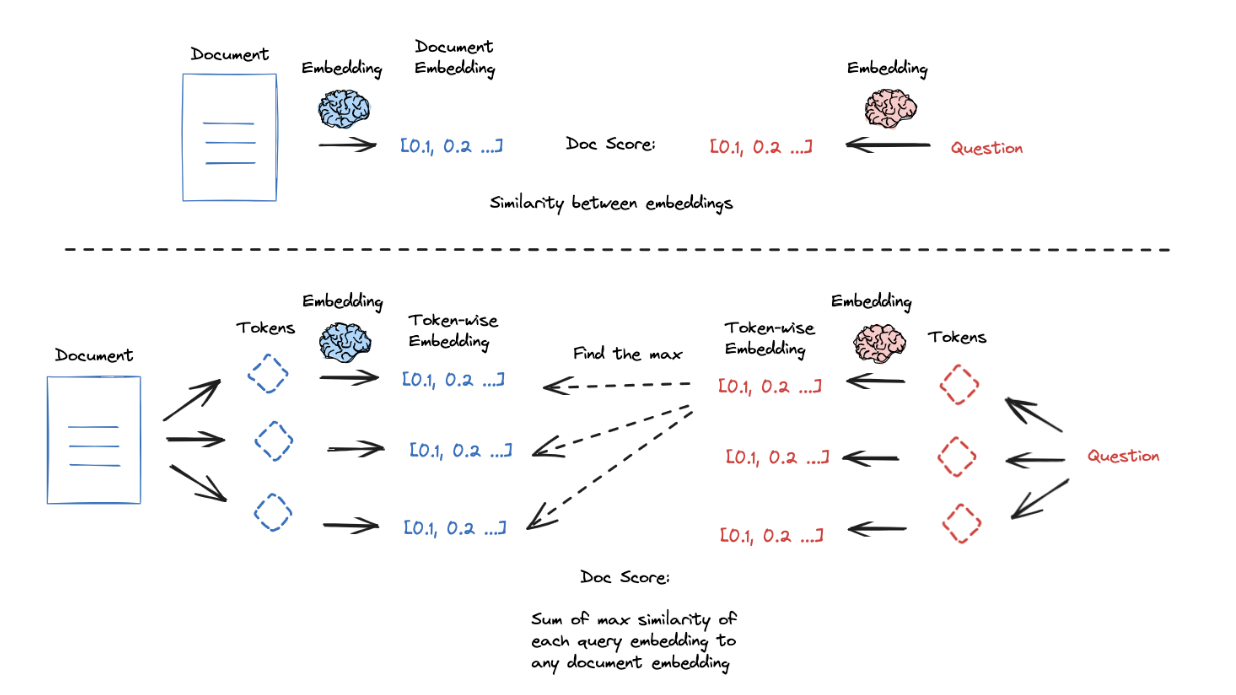
ColBERT is an interesting approach to address this with a higher granularity embeddings: (1) produce a contextually influenced embedding for each token in the document and query, (2) score similarity between each query token and all document tokens, (3) take the max, (4) do this for all query tokens, and (5) take the sum of the max scores (in step 3) for all query tokens to get a query-document similarity score; this token-wise scoring can yield strong results.
There are some additional tricks to improve the quality of your retrieval. Embeddings excel at capturing semantic information, but may struggle with keyword-based queries. Many vector stores offer built-in hybrid-search to combine keyword and semantic similarity, which marries the benefits of both approaches. Furthermore, many vector stores have maximal marginal relevance, which attempts to diversify the results of a search to avoid returning similar and redundant documents.
| Name | When to use | Description |
|---|---|---|
| ColBERT | When higher granularity embeddings are needed. | ColBERT uses contextually influenced embeddings for each token in the document and query to get a granular query-document similarity score. Paper. |
| Hybrid search | When combining keyword-based and semantic similarity. | Hybrid search combines keyword and semantic similarity, marrying the benefits of both approaches. Paper. |
| Maximal Marginal Relevance (MMR) | When needing to diversify search results. | MMR attempts to diversify the results of a search to avoid returning similar and redundant documents. |
See our RAG from Scratch video on ColBERT.
Post-Retrieval Prrocessing
There are several approaches for filtering or ranking retrieved documents.
This is very useful if you are combining documents returned from multiple sources, since it can can down-rank less relevant documents and / or compress similar documents.
| Name | Index Type | Uses an LLM | When to Use | Description |
|---|---|---|---|---|
| Contextual Compression | Any | Sometimes | If you are finding that your retrieved documents contain too much irrelevant information and are distracting the LLM. | This puts a post-processing step on top of another retriever and extracts only the most relevant information from retrieved documents. This can be done with embeddings or an LLM. |
| Ensemble | Any | No | If you have multiple retrieval methods and want to try combining them. | This fetches documents from multiple retrievers and then combines them. |
| Re-ranking | Any | Yes | If you want to rank retrieved documents based upon relevance, especially if you want to combine results from multiple retrieval methods . | Given a query and a list of documents, Rerank indexes the documents from most to least semantically relevant to the query. |
See our RAG from Scratch video on RAG-Fusion (paper), on approach for post-processing across multiple queries: Rewrite the user question from multiple perspectives, retrieve documents for each rewritten question, and combine the ranks of multiple search result lists to produce a single, unified ranking with Reciprocal Rank Fusion (RRF).
Self-correction
Retrieval systems often pass documents to an LLM for generation, a process known as retrieval-augmented generation (RAG). See our tutorial on RAG for more details.
RAG pipeles have various failure modes, including low quality retrieval (e.g., if a user question is out of the domain for the index) and / or hallucinations in generation.
A naive retrieve-generate pipeline has no ability to detect or self-correct from these kinds of errors, as documents are retrieved without any awareness of the generation process.
However, several works have applied self-correction to RAG related to document relevance, hallucinations, and / or answer quality:
- Routing: Adaptive RAG (paper). Route questions to different retrieval approaches, as discussed above
- Fallback: Corrective RAG (paper). Fallback to web search if docs are not relevant to query
- Self-correction: Self-RAG (paper). Fix answers w/ hallucinations or don’t address question
We have various tutorials on these approaches.
In addition, see several videos and cookbooks showcasing self-corrective RAG:
- LangGraph Corrective RAG
- LangGraph combining Adaptive, Self-RAG, and Corrective RAG
- Cookbooks for RAG using LangGraph
See our LangGraph RAG recipes with partners:
Finally, our RAG from Scratch code and video series provide a lot of follow-up details on these approaches.
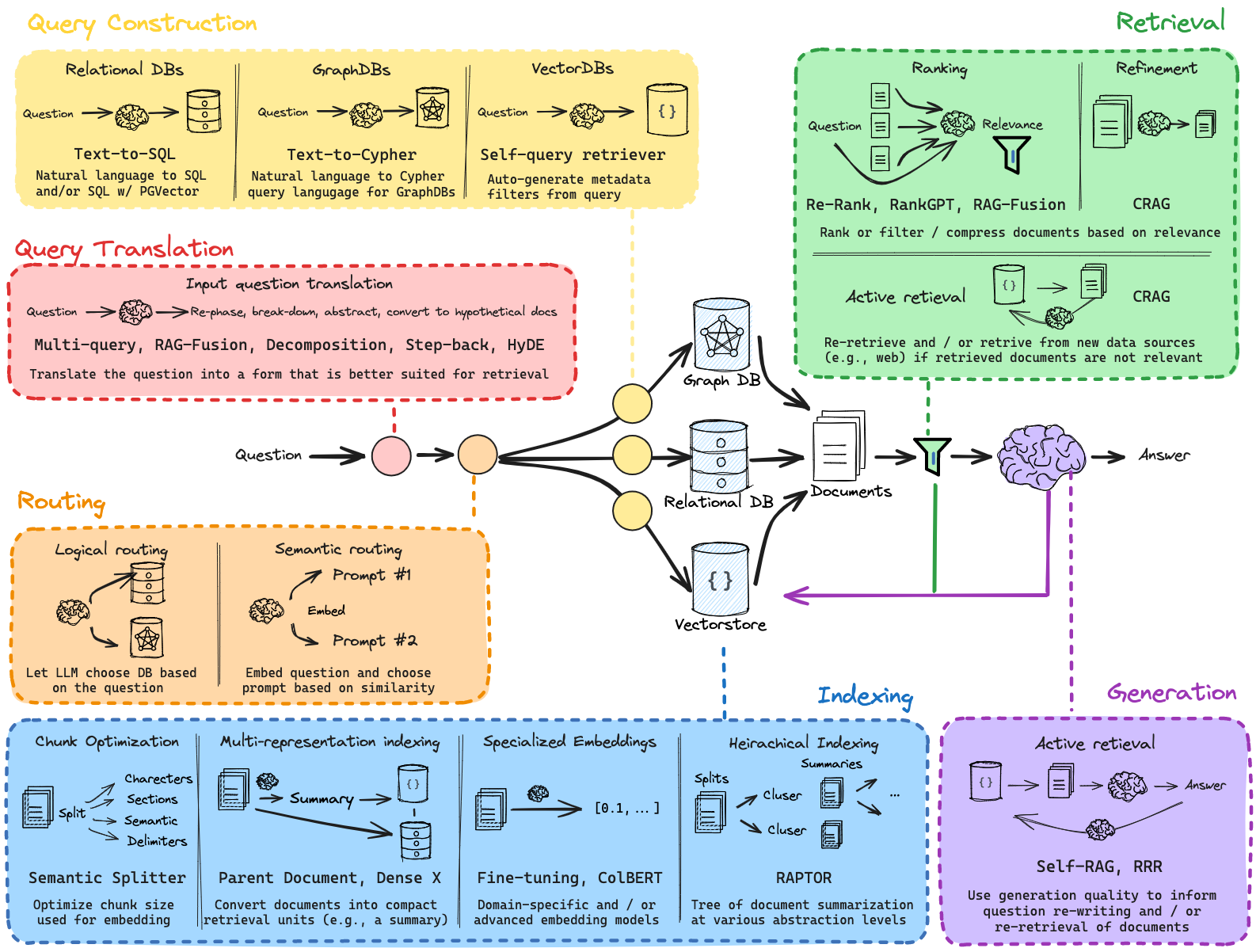
You can see many of these approach captured in this diagram, which provides an overview of some methods and papers in the RAG landscape: